Merge branch 'dev' into 503
7
.flake8
|
|
@ -1,7 +0,0 @@
|
|||
[flake8]
|
||||
extend-ignore = E203, E266, E501
|
||||
# line length is intentionally set to 80 here because black uses Bugbear
|
||||
# See https://github.com/psf/black/blob/master/docs/the_black_code_style.md#line-length for more details
|
||||
max-line-length = 80
|
||||
max-complexity = 18
|
||||
select = B,C,E,F,W,T4,B9
|
||||
53
.mypy.ini
|
|
@ -1,53 +0,0 @@
|
|||
[mypy-mutagen.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-tqdm.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-pathvalidate.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-pick.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-simple_term_menu.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-setuptools.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-requests.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-tomlkit.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-Crypto.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-Cryptodome.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-click.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-PIL.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-cleo.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-deezer.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-appdirs.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-m3u8.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-aiohttp.*]
|
||||
ignore_missing_imports = True
|
||||
|
||||
[mypy-aiofiles.*]
|
||||
ignore_missing_imports = True
|
||||
51
README.md
|
|
@ -1,27 +1,27 @@
|
|||
|
||||

|
||||

|
||||
|
||||
[](https://pepy.tech/project/streamrip)
|
||||
[](https://github.com/python/black)
|
||||
|
||||
A scriptable stream downloader for Qobuz, Tidal, Deezer and SoundCloud.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Features
|
||||
|
||||
- Super fast, as it utilizes concurrent downloads and conversion
|
||||
- Fast, concurrent downloads powered by `aiohttp`
|
||||
- Downloads tracks, albums, playlists, discographies, and labels from Qobuz, Tidal, Deezer, and SoundCloud
|
||||
- Supports downloads of Spotify and Apple Music playlists through [last.fm](https://www.last.fm)
|
||||
- Automatically converts files to a preferred format
|
||||
- Has a database that stores the downloaded tracks' IDs so that repeats are avoided
|
||||
- Easy to customize with the config file
|
||||
- Concurrency and rate limiting
|
||||
- Interactive search for all sources
|
||||
- Highly customizable through the config file
|
||||
- Integration with `youtube-dl`
|
||||
|
||||
## Installation
|
||||
|
||||
First, ensure [Python](https://www.python.org/downloads/) (version 3.8 or greater) and [pip](https://pip.pypa.io/en/stable/installing/) are installed. If you are on Windows, install [Microsoft Visual C++ Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/). Then run the following in the command line:
|
||||
First, ensure [Python](https://www.python.org/downloads/) (version 3.10 or greater) and [pip](https://pip.pypa.io/en/stable/installing/) are installed. Then install `ffmpeg`. You may choose not to install this, but some functionality will be limited.
|
||||
|
||||
```bash
|
||||
pip3 install streamrip --upgrade
|
||||
|
|
@ -35,7 +35,6 @@ rip
|
|||
|
||||
it should show the main help page. If you have no idea what these mean, or are having other issues installing, check out the [detailed installation instructions](https://github.com/nathom/streamrip/wiki#detailed-installation-instructions).
|
||||
|
||||
If you would like to use `streamrip`'s conversion capabilities, download TIDAL videos, or download music from SoundCloud, install [ffmpeg](https://ffmpeg.org/download.html). To download music from YouTube, install [youtube-dl](https://github.com/ytdl-org/youtube-dl#installation).
|
||||
|
||||
### Streamrip beta
|
||||
|
||||
|
|
@ -83,29 +82,24 @@ To set the maximum quality, use the `--max-quality` option to `0, 1, 2, 3, 4`:
|
|||
| 4 | 24 bit, ≤ 192 kHz | Qobuz |
|
||||
|
||||
|
||||
|
||||
```bash
|
||||
rip url --max-quality 3 https://tidal.com/browse/album/147569387
|
||||
rip url --quality 3 https://tidal.com/browse/album/147569387
|
||||
```
|
||||
|
||||
> Using `4` is generally a waste of space. It is impossible for humans to perceive the between sampling rates higher than 44.1 kHz. It may be useful if you're processing/slowing down the audio.
|
||||
|
||||
Search for albums matching `lil uzi vert` on SoundCloud
|
||||
|
||||
```bash
|
||||
rip search --source soundcloud 'lil uzi vert'
|
||||
rip search tidal playlist 'rap'
|
||||
```
|
||||
|
||||

|
||||
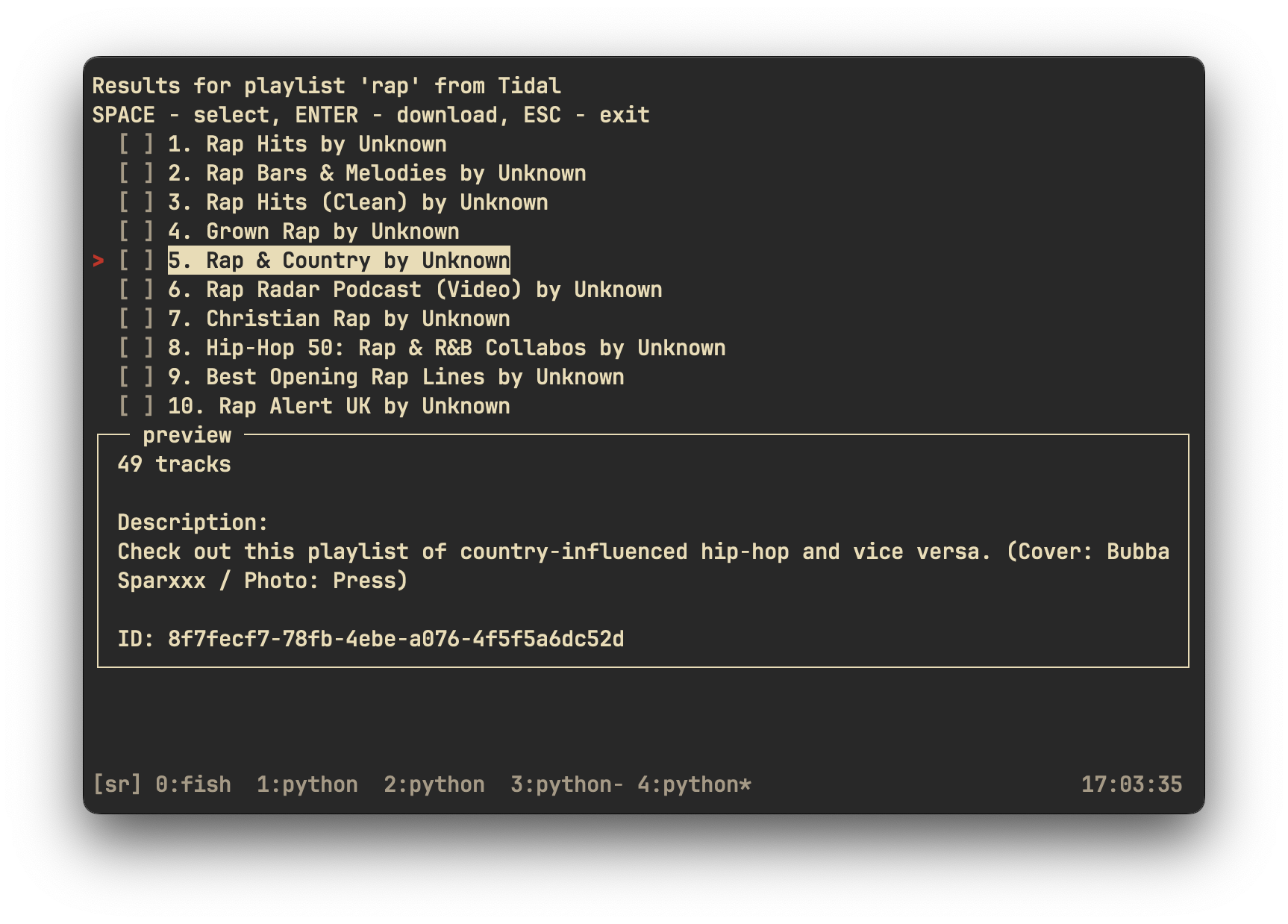
|
||||
|
||||
Search for *Rumours* on Tidal, and download it
|
||||
|
||||
```bash
|
||||
rip search 'fleetwood mac rumours'
|
||||
```
|
||||
|
||||
Want to find some new music? Use the `discover` command (only on Qobuz)
|
||||
|
||||
```bash
|
||||
rip discover --list 'best-sellers'
|
||||
rip search tidal album 'fleetwood mac rumours'
|
||||
```
|
||||
|
||||
Download a last.fm playlist using the lastfm command
|
||||
|
|
@ -114,18 +108,18 @@ Download a last.fm playlist using the lastfm command
|
|||
rip lastfm https://www.last.fm/user/nathan3895/playlists/12126195
|
||||
```
|
||||
|
||||
For extreme customization, see the config file
|
||||
For more customization, see the config file
|
||||
|
||||
```
|
||||
rip config --open
|
||||
rip config open
|
||||
```
|
||||
|
||||
|
||||
|
||||
If you're confused about anything, see the help pages. The main help pages can be accessed by typing `rip` by itself in the command line. The help pages for each command can be accessed with the `-h` flag. For example, to see the help page for the `url` command, type
|
||||
If you're confused about anything, see the help pages. The main help pages can be accessed by typing `rip` by itself in the command line. The help pages for each command can be accessed with the `-help` flag. For example, to see the help page for the `url` command, type
|
||||
|
||||
```
|
||||
rip url -h
|
||||
rip url --help
|
||||
```
|
||||
|
||||
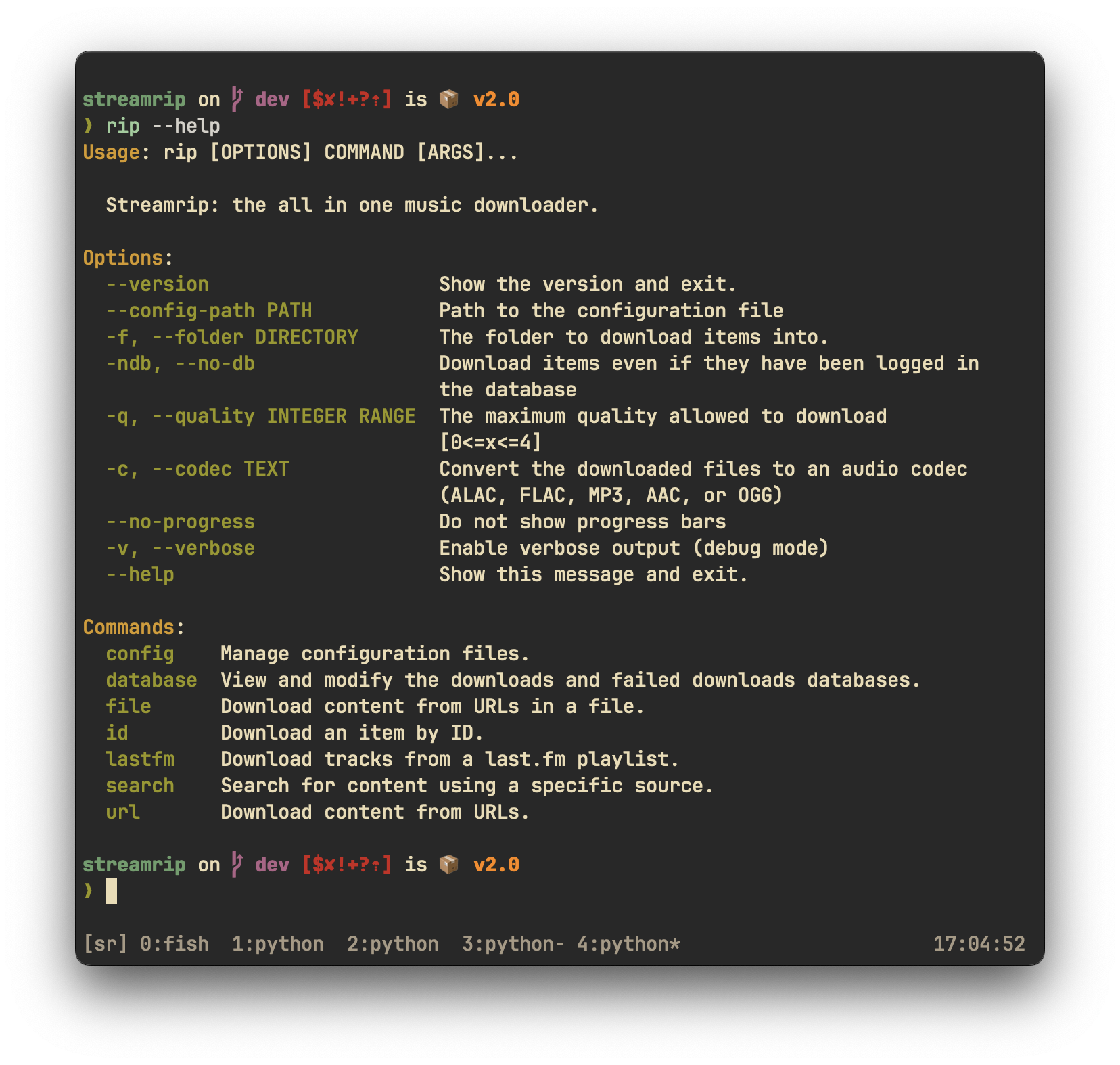
|
||||
|
|
@ -177,13 +171,8 @@ Thanks to Vitiko98, Sorrow446, and DashLt for their contributions to this projec
|
|||
|
||||
## Disclaimer
|
||||
|
||||
I will not be responsible for how **you** use `streamrip`. By using `streamrip`, you agree to the terms and conditions of the Qobuz, Tidal, and Deezer APIs.
|
||||
|
||||
I will not be responsible for how you use `streamrip`. By using `streamrip`, you agree to the terms and conditions of the Qobuz, Tidal, and Deezer APIs.
|
||||
## Sponsorship
|
||||
|
||||
## Donations/Sponsorship
|
||||
|
||||
<a href="https://www.buymeacoffee.com/nathom" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
|
||||
|
||||
|
||||
Consider contributing some funds [here](https://www.buymeacoffee.com/nathom), which will go towards holding
|
||||
the premium subscriptions that I need to debug and improve streamrip. Thanks for your support!
|
||||
Consider becoming a Github sponsor for me if you enjoy my open source software.
|
||||
|
|
|
|||
{kind=link}
|
Before Width: | Height: | Size: 325 KiB |
{kind=link}
|
Before Width: | Height: | Size: 148 KiB |
{kind=link}
|
Before Width: | Height: | Size: 292 KiB After Width: | Height: | Size: 377 KiB |
{kind=link}
|
Before Width: | Height: | Size: 407 KiB After Width: | Height: | Size: 641 KiB |
BIN
demo/playlist_search.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 475 KiB |
|
|
@ -181,6 +181,7 @@ class DeezerClient(Client):
|
|||
)
|
||||
|
||||
dl_info["url"] = url
|
||||
logger.debug("dz track info: %s", track_info)
|
||||
return DeezerDownloadable(self.session, dl_info)
|
||||
|
||||
def _get_encrypted_file_url(
|
||||
|
|
@ -212,5 +213,6 @@ class DeezerClient(Client):
|
|||
path = binascii.hexlify(
|
||||
AES.new(b"jo6aey6haid2Teih", AES.MODE_ECB).encrypt(info_bytes),
|
||||
).decode("utf-8")
|
||||
|
||||
return f"https://e-cdns-proxy-{track_hash[0]}.dzcdn.net/mobile/1/{path}"
|
||||
url = f"https://e-cdns-proxy-{track_hash[0]}.dzcdn.net/mobile/1/{path}"
|
||||
logger.debug("Encrypted file path %s", url)
|
||||
return url
|
||||
|
|
|
|||
|
|
@ -1,6 +1,7 @@
|
|||
import asyncio
|
||||
import itertools
|
||||
import logging
|
||||
import random
|
||||
import re
|
||||
|
||||
from ..config import Config
|
||||
|
|
@ -8,8 +9,9 @@ from ..exceptions import NonStreamableError
|
|||
from .client import Client
|
||||
from .downloadable import SoundcloudDownloadable
|
||||
|
||||
# e.g. 123456-293847-121314-209849
|
||||
USER_ID = "-".join(str(random.randint(111111, 999999)) for _ in range(4))
|
||||
BASE = "https://api-v2.soundcloud.com"
|
||||
SOUNDCLOUD_USER_ID = "672320-86895-162383-801513"
|
||||
STOCK_URL = "https://soundcloud.com/"
|
||||
|
||||
# for playlists
|
||||
|
|
@ -36,7 +38,7 @@ class SoundcloudClient(Client):
|
|||
async def login(self):
|
||||
self.session = await self.get_session()
|
||||
client_id, app_version = self.config.client_id, self.config.app_version
|
||||
if not client_id or not app_version or not (await self._announce()):
|
||||
if not client_id or not app_version or not (await self._announce_success()):
|
||||
client_id, app_version = await self._refresh_tokens()
|
||||
# update file and session configs and save to disk
|
||||
cf = self.global_config.file.soundcloud
|
||||
|
|
@ -54,13 +56,14 @@ class SoundcloudClient(Client):
|
|||
"""Fetch metadata for an item in Soundcloud API.
|
||||
|
||||
Args:
|
||||
----
|
||||
|
||||
item_id (str): Plain soundcloud item ID (e.g 1633786176)
|
||||
media_type (str): track or playlist
|
||||
|
||||
Returns:
|
||||
-------
|
||||
API response.
|
||||
|
||||
API response. The item IDs for the tracks in the playlist are modified to
|
||||
include resolution status.
|
||||
"""
|
||||
if media_type == "track":
|
||||
# parse custom id that we injected
|
||||
|
|
@ -71,6 +74,82 @@ class SoundcloudClient(Client):
|
|||
else:
|
||||
raise Exception(f"{media_type} not supported")
|
||||
|
||||
async def search(
|
||||
self,
|
||||
media_type: str,
|
||||
query: str,
|
||||
limit: int = 50,
|
||||
offset: int = 0,
|
||||
) -> list[dict]:
|
||||
# TODO: implement pagination
|
||||
assert media_type in ("track", "playlist"), f"Cannot search for {media_type}"
|
||||
params = {
|
||||
"q": query,
|
||||
"facet": "genre",
|
||||
"user_id": USER_ID,
|
||||
"limit": limit,
|
||||
"offset": offset,
|
||||
"linked_partitioning": "1",
|
||||
}
|
||||
resp, status = await self._api_request(f"search/{media_type}s", params=params)
|
||||
assert status == 200
|
||||
return [resp]
|
||||
|
||||
async def get_downloadable(self, item_info: str, _) -> SoundcloudDownloadable:
|
||||
# We have `get_metadata` overwrite the "id" field so that it contains
|
||||
# some extra information we need to download soundcloud tracks
|
||||
|
||||
# item_id is the soundcloud ID of the track
|
||||
# download_url is either the url that points to an mp3 download or ""
|
||||
# if download_url == '_non_streamable' then we raise an exception
|
||||
|
||||
infos: list[str] = item_info.split("|")
|
||||
logger.debug(f"{infos=}")
|
||||
assert len(infos) == 2, infos
|
||||
item_id, download_info = infos
|
||||
assert re.match(r"\d+", item_id) is not None
|
||||
|
||||
if download_info == self.NON_STREAMABLE:
|
||||
raise NonStreamableError(item_info)
|
||||
|
||||
if download_info == self.ORIGINAL_DOWNLOAD:
|
||||
resp_json, status = await self._api_request(f"tracks/{item_id}/download")
|
||||
assert status == 200
|
||||
return SoundcloudDownloadable(
|
||||
self.session,
|
||||
{"url": resp_json["redirectUri"], "type": "original"},
|
||||
)
|
||||
|
||||
if download_info == self.NOT_RESOLVED:
|
||||
raise NotImplementedError(item_info)
|
||||
|
||||
# download_info contains mp3 stream url
|
||||
resp_json, status = await self._request(download_info)
|
||||
return SoundcloudDownloadable(
|
||||
self.session,
|
||||
{"url": resp_json["url"], "type": "mp3"},
|
||||
)
|
||||
|
||||
async def resolve_url(self, url: str) -> dict:
|
||||
"""Get metadata of the item pointed to by a soundcloud url.
|
||||
|
||||
This is necessary only for soundcloud because they don't store
|
||||
the item IDs in their url. See SoundcloudURL.into_pending for example
|
||||
usage.
|
||||
|
||||
Args:
|
||||
url (str): Url to resolve.
|
||||
|
||||
Returns:
|
||||
API response for item.
|
||||
"""
|
||||
resp, status = await self._api_request("resolve", params={"url": url})
|
||||
assert status == 200
|
||||
if resp["kind"] == "track":
|
||||
resp["id"] = self._get_custom_id(resp)
|
||||
|
||||
return resp
|
||||
|
||||
async def _get_track(self, item_id: str):
|
||||
resp, status = await self._api_request(f"tracks/{item_id}")
|
||||
assert status == 200
|
||||
|
|
@ -140,62 +219,6 @@ class SoundcloudClient(Client):
|
|||
assert url is not None
|
||||
return f"{item_id}|{url}"
|
||||
|
||||
async def get_downloadable(self, item_info: str, _) -> SoundcloudDownloadable:
|
||||
# We have `get_metadata` overwrite the "id" field so that it contains
|
||||
# some extra information we need to download soundcloud tracks
|
||||
|
||||
# item_id is the soundcloud ID of the track
|
||||
# download_url is either the url that points to an mp3 download or ""
|
||||
# if download_url == '_non_streamable' then we raise an exception
|
||||
|
||||
infos: list[str] = item_info.split("|")
|
||||
logger.debug(f"{infos=}")
|
||||
assert len(infos) == 2, infos
|
||||
item_id, download_info = infos
|
||||
assert re.match(r"\d+", item_id) is not None
|
||||
|
||||
if download_info == self.NON_STREAMABLE:
|
||||
raise NonStreamableError(item_info)
|
||||
|
||||
if download_info == self.ORIGINAL_DOWNLOAD:
|
||||
resp_json, status = await self._api_request(f"tracks/{item_id}/download")
|
||||
assert status == 200
|
||||
return SoundcloudDownloadable(
|
||||
self.session,
|
||||
{"url": resp_json["redirectUri"], "type": "original"},
|
||||
)
|
||||
|
||||
if download_info == self.NOT_RESOLVED:
|
||||
raise NotImplementedError(item_info)
|
||||
|
||||
# download_info contains mp3 stream url
|
||||
resp_json, status = await self._request(download_info)
|
||||
return SoundcloudDownloadable(
|
||||
self.session,
|
||||
{"url": resp_json["url"], "type": "mp3"},
|
||||
)
|
||||
|
||||
async def search(
|
||||
self,
|
||||
media_type: str,
|
||||
query: str,
|
||||
limit: int = 50,
|
||||
offset: int = 0,
|
||||
) -> list[dict]:
|
||||
# TODO: implement pagination
|
||||
assert media_type in ("track", "playlist"), f"Cannot search for {media_type}"
|
||||
params = {
|
||||
"q": query,
|
||||
"facet": "genre",
|
||||
"user_id": SOUNDCLOUD_USER_ID,
|
||||
"limit": limit,
|
||||
"offset": offset,
|
||||
"linked_partitioning": "1",
|
||||
}
|
||||
resp, status = await self._api_request(f"search/{media_type}s", params=params)
|
||||
assert status == 200
|
||||
return [resp]
|
||||
|
||||
async def _api_request(self, path, params=None, headers=None):
|
||||
url = f"{BASE}/{path}"
|
||||
return await self._request(url, params=params, headers=headers)
|
||||
|
|
@ -227,12 +250,7 @@ class SoundcloudClient(Client):
|
|||
async with self.session.get(url, params=_params, headers=headers) as resp:
|
||||
return await resp.content.read(), resp.status
|
||||
|
||||
async def _resolve_url(self, url: str) -> dict:
|
||||
resp, status = await self._api_request("resolve", params={"url": url})
|
||||
assert status == 200
|
||||
return resp
|
||||
|
||||
async def _announce(self):
|
||||
async def _announce_success(self):
|
||||
url = f"{BASE}/announcements"
|
||||
_, status = await self._request_body(url)
|
||||
return status == 200
|
||||
|
|
|
|||
|
|
@ -3,9 +3,6 @@ from contextlib import nullcontext
|
|||
|
||||
from ..config import DownloadsConfig
|
||||
|
||||
INF = 9999
|
||||
|
||||
|
||||
_unlimited = nullcontext()
|
||||
_global_semaphore: None | tuple[int, asyncio.Semaphore] = None
|
||||
|
||||
|
|
@ -23,14 +20,16 @@ def global_download_semaphore(c: DownloadsConfig) -> asyncio.Semaphore | nullcon
|
|||
global _unlimited, _global_semaphore
|
||||
|
||||
if c.concurrency:
|
||||
max_connections = c.max_connections if c.max_connections > 0 else INF
|
||||
max_connections = c.max_connections if c.max_connections > 0 else None
|
||||
else:
|
||||
max_connections = 1
|
||||
|
||||
assert max_connections > 0
|
||||
if max_connections == INF:
|
||||
if max_connections is None:
|
||||
return _unlimited
|
||||
|
||||
if max_connections <= 0:
|
||||
raise Exception(f"{max_connections = } too small")
|
||||
|
||||
if _global_semaphore is None:
|
||||
_global_semaphore = (max_connections, asyncio.Semaphore(max_connections))
|
||||
|
||||
|
|
|
|||
|
|
@ -157,7 +157,6 @@ class AlbumMetadata:
|
|||
|
||||
@classmethod
|
||||
def from_deezer(cls, resp: dict) -> AlbumMetadata | None:
|
||||
print(resp.keys())
|
||||
album = resp.get("title", "Unknown Album")
|
||||
tracktotal = typed(resp.get("track_total", 0) or resp.get("nb_tracks", 0), int)
|
||||
disctotal = typed(resp["tracks"][-1]["disk_number"], int)
|
||||
|
|
|
|||
|
|
@ -39,7 +39,7 @@ class ArtistSummary(Summary):
|
|||
return "artist"
|
||||
|
||||
def summarize(self) -> str:
|
||||
return self.name
|
||||
return clean(self.name)
|
||||
|
||||
def preview(self) -> str:
|
||||
return f"{self.num_albums} Albums\n\nID: {self.id}"
|
||||
|
|
@ -73,7 +73,8 @@ class TrackSummary(Summary):
|
|||
return "track"
|
||||
|
||||
def summarize(self) -> str:
|
||||
return f"{self.name} by {self.artist}"
|
||||
# This char breaks the menu for some reason
|
||||
return f"{clean(self.name)} by {clean(self.artist)}"
|
||||
|
||||
def preview(self) -> str:
|
||||
return f"Released on:\n{self.date_released}\n\nID: {self.id}"
|
||||
|
|
@ -119,7 +120,7 @@ class AlbumSummary(Summary):
|
|||
return "album"
|
||||
|
||||
def summarize(self) -> str:
|
||||
return f"{self.name} by {self.artist}"
|
||||
return f"{clean(self.name)} by {clean(self.artist)}"
|
||||
|
||||
def preview(self) -> str:
|
||||
return f"Date released:\n{self.date_released}\n\n{self.num_tracks} Tracks\n\nID: {self.id}"
|
||||
|
|
@ -188,11 +189,14 @@ class PlaylistSummary(Summary):
|
|||
description: str
|
||||
|
||||
def summarize(self) -> str:
|
||||
return f"{self.name} by {self.creator}"
|
||||
name = clean(self.name)
|
||||
creator = clean(self.creator)
|
||||
return f"{name} by {creator}"
|
||||
|
||||
def preview(self) -> str:
|
||||
desc = clean(self.description, trunc=False)
|
||||
wrapped = "\n".join(
|
||||
textwrap.wrap(self.description, os.get_terminal_size().columns - 4 or 70),
|
||||
textwrap.wrap(desc, os.get_terminal_size().columns - 4 or 70),
|
||||
)
|
||||
return f"{self.num_tracks} tracks\n\nDescription:\n{wrapped}\n\nID: {self.id}"
|
||||
|
||||
|
|
@ -214,6 +218,7 @@ class PlaylistSummary(Summary):
|
|||
item.get("tracks_count")
|
||||
or item.get("nb_tracks")
|
||||
or item.get("numberOfTracks")
|
||||
or len(item.get("tracks", []))
|
||||
or -1
|
||||
)
|
||||
description = item.get("description") or "No description"
|
||||
|
|
@ -284,3 +289,11 @@ class SearchResults:
|
|||
}
|
||||
for i in self.results
|
||||
]
|
||||
|
||||
|
||||
def clean(s: str, trunc=True) -> str:
|
||||
s = s.replace("|", "").replace("\n", "")
|
||||
if trunc:
|
||||
max_chars = 50
|
||||
return s[:max_chars]
|
||||
return s
|
||||
|
|
|
|||
|
|
@ -25,8 +25,6 @@ class ProgressManager:
|
|||
BarColumn(bar_width=None),
|
||||
"[progress.percentage]{task.percentage:>3.1f}%",
|
||||
"•",
|
||||
# DownloadColumn(),
|
||||
# "•",
|
||||
TransferSpeedColumn(),
|
||||
"•",
|
||||
TimeRemainingColumn(),
|
||||
|
|
|
|||
|
|
@ -37,8 +37,14 @@ def coro(f):
|
|||
"--config-path",
|
||||
default=DEFAULT_CONFIG_PATH,
|
||||
help="Path to the configuration file",
|
||||
type=click.Path(readable=True, writable=True),
|
||||
)
|
||||
@click.option(
|
||||
"-f",
|
||||
"--folder",
|
||||
help="The folder to download items into.",
|
||||
type=click.Path(file_okay=False, dir_okay=True),
|
||||
)
|
||||
@click.option("-f", "--folder", help="The folder to download items into.")
|
||||
@click.option(
|
||||
"-ndb",
|
||||
"--no-db",
|
||||
|
|
@ -47,11 +53,14 @@ def coro(f):
|
|||
is_flag=True,
|
||||
)
|
||||
@click.option(
|
||||
"-q", "--quality", help="The maximum quality allowed to download", type=int
|
||||
"-q",
|
||||
"--quality",
|
||||
help="The maximum quality allowed to download",
|
||||
type=click.IntRange(min=0, max=4),
|
||||
)
|
||||
@click.option(
|
||||
"-c",
|
||||
"--convert",
|
||||
"--codec",
|
||||
help="Convert the downloaded files to an audio codec (ALAC, FLAC, MP3, AAC, or OGG)",
|
||||
)
|
||||
@click.option(
|
||||
|
|
@ -67,7 +76,7 @@ def coro(f):
|
|||
is_flag=True,
|
||||
)
|
||||
@click.pass_context
|
||||
def rip(ctx, config_path, folder, no_db, quality, convert, no_progress, verbose):
|
||||
def rip(ctx, config_path, folder, no_db, quality, codec, no_progress, verbose):
|
||||
"""Streamrip: the all in one music downloader."""
|
||||
global logger
|
||||
logging.basicConfig(
|
||||
|
|
@ -113,7 +122,8 @@ def rip(ctx, config_path, folder, no_db, quality, convert, no_progress, verbose)
|
|||
return
|
||||
|
||||
# set session config values to command line args
|
||||
c.session.database.downloads_enabled = not no_db
|
||||
if no_db:
|
||||
c.session.database.downloads_enabled = False
|
||||
if folder is not None:
|
||||
c.session.downloads.folder = folder
|
||||
|
||||
|
|
@ -123,10 +133,10 @@ def rip(ctx, config_path, folder, no_db, quality, convert, no_progress, verbose)
|
|||
c.session.deezer.quality = quality
|
||||
c.session.soundcloud.quality = quality
|
||||
|
||||
if convert is not None:
|
||||
if codec is not None:
|
||||
c.session.conversion.enabled = True
|
||||
assert convert.upper() in ("ALAC", "FLAC", "OGG", "MP3", "AAC")
|
||||
c.session.conversion.codec = convert.upper()
|
||||
assert codec.upper() in ("ALAC", "FLAC", "OGG", "MP3", "AAC")
|
||||
c.session.conversion.codec = codec.upper()
|
||||
|
||||
if no_progress:
|
||||
c.session.cli.progress_bars = False
|
||||
|
|
|
|||
|
|
@ -9,7 +9,17 @@ from .. import db
|
|||
from ..client import Client, DeezerClient, QobuzClient, SoundcloudClient, TidalClient
|
||||
from ..config import Config
|
||||
from ..console import console
|
||||
from ..media import Media, Pending, PendingLastfmPlaylist, remove_artwork_tempdirs
|
||||
from ..media import (
|
||||
Media,
|
||||
Pending,
|
||||
PendingAlbum,
|
||||
PendingArtist,
|
||||
PendingLabel,
|
||||
PendingLastfmPlaylist,
|
||||
PendingPlaylist,
|
||||
PendingSingle,
|
||||
remove_artwork_tempdirs,
|
||||
)
|
||||
from ..metadata import SearchResults
|
||||
from ..progress import clear_progress
|
||||
from .parse_url import parse_url
|
||||
|
|
@ -24,6 +34,7 @@ class Main:
|
|||
* Logs in to Clients and prompts for credentials
|
||||
* Handles output logging
|
||||
* Handles downloading Media
|
||||
* Handles interactive search
|
||||
|
||||
User input (urls) -> Main --> Download files & Output messages to terminal
|
||||
"""
|
||||
|
|
@ -71,6 +82,32 @@ class Main:
|
|||
)
|
||||
logger.debug("Added url=%s", url)
|
||||
|
||||
async def add_by_id(self, source: str, media_type: str, id: str):
|
||||
client = await self.get_logged_in_client(source)
|
||||
self._add_by_id_client(client, media_type, id)
|
||||
|
||||
async def add_all_by_id(self, info: list[tuple[str, str, str]]):
|
||||
sources = set(s for s, _, _ in info)
|
||||
clients = {s: await self.get_logged_in_client(s) for s in sources}
|
||||
for source, media_type, id in info:
|
||||
self._add_by_id_client(clients[source], media_type, id)
|
||||
|
||||
def _add_by_id_client(self, client: Client, media_type: str, id: str):
|
||||
if media_type == "track":
|
||||
item = PendingSingle(id, client, self.config, self.database)
|
||||
elif media_type == "album":
|
||||
item = PendingAlbum(id, client, self.config, self.database)
|
||||
elif media_type == "playlist":
|
||||
item = PendingPlaylist(id, client, self.config, self.database)
|
||||
elif media_type == "label":
|
||||
item = PendingLabel(id, client, self.config, self.database)
|
||||
elif media_type == "artist":
|
||||
item = PendingArtist(id, client, self.config, self.database)
|
||||
else:
|
||||
raise Exception(media_type)
|
||||
|
||||
self.pending.append(item)
|
||||
|
||||
async def add_all(self, urls: list[str]):
|
||||
"""Add multiple urls concurrently as pending items."""
|
||||
parsed = [parse_url(url) for url in urls]
|
||||
|
|
@ -151,8 +188,8 @@ class Main:
|
|||
)
|
||||
assert isinstance(choices, list)
|
||||
|
||||
await self.add_all(
|
||||
[self.dummy_url(source, media_type, item.id) for item, _ in choices],
|
||||
await self.add_all_by_id(
|
||||
[(source, media_type, item.id) for item, _ in choices],
|
||||
)
|
||||
|
||||
else:
|
||||
|
|
@ -175,11 +212,8 @@ class Main:
|
|||
console.print("[yellow]No items chosen. Exiting.")
|
||||
else:
|
||||
choices = search_results.get_choices(chosen_ind)
|
||||
await self.add_all(
|
||||
[
|
||||
self.dummy_url(source, item.media_type(), item.id)
|
||||
for item in choices
|
||||
],
|
||||
await self.add_all_by_id(
|
||||
[(source, item.media_type(), item.id) for item in choices],
|
||||
)
|
||||
|
||||
async def search_take_first(self, source: str, media_type: str, query: str):
|
||||
|
|
@ -258,6 +292,3 @@ class Main:
|
|||
# may be able to share downloaded artwork in the same `rip` session
|
||||
# We don't know that a cover will not be used again until end of execution
|
||||
remove_artwork_tempdirs()
|
||||
|
||||
async def add_by_id(self, source: str, media_type: str, id: str):
|
||||
await self.add(f"http://{source}.com/{media_type}/{id}")
|
||||
|
|
|
|||
|
|
@ -14,11 +14,17 @@ from ..media import (
|
|||
PendingPlaylist,
|
||||
PendingSingle,
|
||||
)
|
||||
from .validation_regexps import (
|
||||
QOBUZ_INTERPRETER_URL_REGEX,
|
||||
SOUNDCLOUD_URL_REGEX,
|
||||
URL_REGEX,
|
||||
|
||||
URL_REGEX = re.compile(
|
||||
r"https?://(?:www|open|play|listen)?\.?(qobuz|tidal|deezer)\.com(?:(?:/(album|artist|track|playlist|video|label))|(?:\/[-\w]+?))+\/([-\w]+)",
|
||||
)
|
||||
SOUNDCLOUD_URL_REGEX = re.compile(r"https://soundcloud.com/[-\w:/]+")
|
||||
LASTFM_URL_REGEX = re.compile(r"https://www.last.fm/user/\w+/playlists/\w+")
|
||||
QOBUZ_INTERPRETER_URL_REGEX = re.compile(
|
||||
r"https?://www\.qobuz\.com/\w\w-\w\w/interpreter/[-\w]+/[-\w]+",
|
||||
)
|
||||
DEEZER_DYNAMIC_LINK_REGEX = re.compile(r"https://deezer\.page\.link/\w+")
|
||||
YOUTUBE_URL_REGEX = re.compile(r"https://www\.youtube\.com/watch\?v=[-\w]+")
|
||||
|
||||
|
||||
class URL(ABC):
|
||||
|
|
@ -134,7 +140,7 @@ class SoundcloudURL(URL):
|
|||
config: Config,
|
||||
db: Database,
|
||||
) -> Pending:
|
||||
resolved = await client._resolve_url(self.url)
|
||||
resolved = await client.resolve_url(self.url)
|
||||
media_type = resolved["kind"]
|
||||
item_id = str(resolved["id"])
|
||||
if media_type == "track":
|
||||
|
|
|
|||
|
|
@ -1,12 +0,0 @@
|
|||
import re
|
||||
|
||||
URL_REGEX = re.compile(
|
||||
r"https?://(?:www|open|play|listen)?\.?(qobuz|tidal|deezer)\.com(?:(?:/(album|artist|track|playlist|video|label))|(?:\/[-\w]+?))+\/([-\w]+)",
|
||||
)
|
||||
SOUNDCLOUD_URL_REGEX = re.compile(r"https://soundcloud.com/[-\w:/]+")
|
||||
LASTFM_URL_REGEX = re.compile(r"https://www.last.fm/user/\w+/playlists/\w+")
|
||||
QOBUZ_INTERPRETER_URL_REGEX = re.compile(
|
||||
r"https?://www\.qobuz\.com/\w\w-\w\w/interpreter/[-\w]+/[-\w]+",
|
||||
)
|
||||
DEEZER_DYNAMIC_LINK_REGEX = re.compile(r"https://deezer\.page\.link/\w+")
|
||||
YOUTUBE_URL_REGEX = re.compile(r"https://www\.youtube\.com/watch\?v=[-\w]+")
|
||||