-**📦 Get ArchiveBox with `docker` / `apt` / `brew` / `pip3` / `nix` / etc. ([see Quickstart below](#quickstart)).** +**📦 Install ArchiveBox using your preferred method: `docker` / `pip` / `apt` / `brew` / etc. ([see full Quickstart below](#quickstart)).** -```bash -# Get ArchiveBox with Docker Compose (recommended) or Docker -curl -sSL 'https://docker-compose.archivebox.io' > docker-compose.yml -docker pull archivebox/archivebox -# Or install with your preferred package manager (see Quickstart below for apt, brew, and more) +
+
+
+Open
+Expand for quick copy-pastable install commands... ⤵️
++
mkdir ~/archivebox; cd ~/archivebox # create a dir somewhere for your archivebox data
+
+# Option A: Get ArchiveBox with Docker Compose (recommended):
+curl -sSL 'https://docker-compose.archivebox.io' > docker-compose.yml # edit options in this file as-needed
+docker compose run archivebox init --setup
+# docker compose run archivebox add 'https://example.com'
+# docker compose run archivebox help
+# docker compose up
+
+
+# Option B: Or use it as a plain Docker container:
+docker run -it -v $PWD:/data archivebox/archivebox init --setup
+# docker run -it -v $PWD:/data archivebox/archivebox add 'https://example.com'
+# docker run -it -v $PWD:/data archivebox/archivebox help
+# docker run -it -v $PWD:/data -p 8000:8000 archivebox/archivebox
+
+
+# Option C: Or install it with your preferred pkg manager (see Quickstart below for apt, brew, and more)
pip install archivebox
-
-# Or use the optional auto setup script to install it
+archivebox init --setup
+# archviebox add 'https://example.com'
+# archivebox help
+# archivebox server 0.0.0.0:8000
+
+
+# Option D: Or use the optional auto setup script to install it
curl -sSL 'https://get.archivebox.io' | sh
-```
++Open
http://localhost:8000 to see your server's Web UI ➡️
+-**🔢 Example usage: adding links to archive.** -```bash -archivebox add 'https://example.com' # add URLs one at a time -archivebox add < ~/Downloads/bookmarks.json # or pipe in URLs in any text-based format -archivebox schedule --every=day --depth=1 https://example.com/rss.xml # or auto-import URLs regularly on a schedule -``` -**🔢 Example usage: viewing the archived content.** -```bash -archivebox server 0.0.0.0:8000 # use the interactive web UI -archivebox list 'https://example.com' # use the CLI commands (--help for more) -ls ./archive/*/index.json # or browse directly via the filesystem -```
@@ -123,12 +125,23 @@ ls ./archive/*/index.json # or browse directly via the filesyste ## 🤝 Professional Integration -*[Contact us](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102) if your institution/org wants to use ArchiveBox professionally.* +ArchiveBox is free for everyone to self-host, but we also provide support, security review, and custom integrations to help NGOs, governments, and other organizations [run ArchiveBox professionally](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102): -- setup & support, team permissioning, hashing, audit logging, backups, custom archiving etc. -- for **individuals**, **NGOs**, **academia**, **governments**, **journalism**, **law**, and more... +- 🗞️ **Journalists:** + `crawling and collecting research`, `preserving quoted material`, `fact-checking and review` +- ⚖️ **Lawyers:** + `collecting & preserving evidence`, `hashing / integrity checking / chain-of-custody`, `tagging & review` +- 🔬 **Researchers:** + `analyzing social media trends`, `collecting LLM training data`, `crawling to feed other pipelines` +- 👩🏽 **Individuals:** + `saving legacy social media / memoirs`, `preserving portfolios / resume`, `backing up news articles` -*We are a 501(c)(3) nonprofit and all our work goes towards supporting open-source development.* +> ***[Contact our team](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102)** if your institution/org wants to use ArchiveBox professionally.* +> +> - setup & support, team permissioning, hashing, audit logging, backups, custom archiving etc. +> - for **individuals**, **NGOs**, **academia**, **governments**, **journalism**, **law**, and more... + +*We are a 🏛️ 501(c)(3) nonprofit and all our work goes towards supporting open-source development.*
@@ -137,6 +150,8 @@ ls ./archive/*/index.json # or browse directly via the filesyste
@@ -146,7 +161,7 @@ ls ./archive/*/index.json # or browse directly via the filesyste #### ✳️ Easy Setup -
+
👍 Docker Compose is recommended for the easiest install/update UX + best security + all the extras out-of-the-box. @@ -155,9 +170,10 @@ ls ./archive/*/index.json # or browse directly via the filesysteInstall Docker on your system (if not already installed).
Download the
-Run the initial setup and create an admin user.
+ Run the initial setup to create an admin user (or set ADMIN_USER/PASS in docker-compose.yml)
Next steps: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
@@ -187,6 +203,7 @@ docker run -v $PWD:/data -it archivebox/archivebox init --setup
@@ -216,8 +233,41 @@ See "Against curl | sh as a
#### 🛠 Package Manager Setup
+
+
@@ -345,7 +368,7 @@ See below for usage examples using the CLI, W
✨ Alpha (contributors wanted!): for more info, see the: Electron ArchiveBox repo. -
+
- -##### Bare Metal Usage (`pip`/`apt`/`brew`/etc.) - -
-
- -##### Docker Compose Usage
+
- -##### Docker Usage
+
+ +
+ +
+
+ +> [!TIP] +> Whether in Docker or not, ArchiveBox commands work the same way, and can be used to access the same data on-disk. +> For example, you could run the Web UI in Docker Compose, and run one-off commands with `pip`-installed ArchiveBox. + +
-#### Next Steps - -- `archivebox help/version` to see the list of available subcommands and currently installed version info -- `archivebox setup/init/config/status/manage` to administer your collection -- `archivebox add/schedule/remove/update/list/shell/oneshot` to manage Snapshots in the archive -- `archivebox schedule` to pull in fresh URLs regularly from [bookmarks/history/Pocket/Pinboard/RSS/etc.](#input-formats) - - -#### 🖥 Web UI Usage - -##### Start the Web Server -```bash -# Bare metal (pip/apt/brew/etc): -archivebox server 0.0.0.0:8000 # open http://127.0.0.1:8000 to view it - -# Docker Compose: -docker compose up - -# Docker: -docker run -v $PWD:/data -it -p 8000:8000 archivebox/archivebox -``` - -##### Allow Public Access or Create an Admin User -```bash -archivebox manage createsuperuser # create a new admin username & pass -# OR # OR -archivebox config --set PUBLIC_ADD_VIEW=True # allow guests to submit URLs -archivebox config --set PUBLIC_SNAPSHOTS=True # allow guests to see snapshot content -archivebox config --set PUBLIC_INDEX=True # allow guests to see list of all snapshots - -# restart the server to apply any config changes -``` - -*Docker hint:* Set the [`ADMIN_USERNAME` & `ADMIN_PASSWORD`)](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#admin_username--admin_password) env variables to auto-create an admin user on first-run. - -#### 🗄 SQL/Python/Filesystem Usage - -```bash -sqlite3 ./index.sqlite3 # run SQL queries on your index -archivebox shell # explore the Python API in a REPL -ls ./archive/*/index.html # or inspect snapshots on the filesystem -```
- ---- - -
 @@ -1047,7 +1093,7 @@ ArchiveBox aims to enable more of the internet to be saved from deterioration by
@@ -1047,7 +1093,7 @@ ArchiveBox aims to enable more of the internet to be saved from deterioration by

docker-compose (macOS/Linux/Windows) 👈 recommended (click to expand)
👍 Docker Compose is recommended for the easiest install/update UX + best security + all the extras out-of-the-box. @@ -155,9 +170,10 @@ ls ./archive/*/index.json # or browse directly via the filesyste
docker-compose.yml file into a new empty directory (can be anywhere).
mkdir ~/archivebox && cd ~/archivebox
-curl -O 'https://raw.githubusercontent.com/ArchiveBox/ArchiveBox/dev/docker-compose.yml'
+# Read and edit docker-compose.yml options as-needed after downloading
+curl -sSL 'https://docker-compose.archivebox.io' > docker-compose.yml
docker compose run archivebox init --setup
docker run -v $PWD:/data -p 8000:8000 archivebox/archivebox
# completely optional, CLI can always be used without running a server
# docker run -v $PWD:/data -it [subcommand] [--args]
+docker run -v $PWD:/data -it archivebox/archivebox help
-
+
+
+
+See the
+
+
+
+
apt (Ubuntu/Debian)
+
pip (macOS/Linux/BSD)
++
-
+
+
- Install Python >= v3.10 and Node >= v18 on your system (if not already installed). +
- Install the ArchiveBox package using
pip3(orpipx). +
+pip3 install archivebox +
+ - Create a new empty directory and initialize your collection (can be anywhere).
+
+mkdir ~/archivebox && cd ~/archivebox +archivebox init --setup +# install any missing extras like wget/git/ripgrep/etc. manually as needed +
+ - Optional: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
+
+archivebox server 0.0.0.0:8000 +# completely optional, CLI can always be used without running a server +# archivebox [subcommand] [--args] +archivebox help +
+
+See the
pip-archivebox repo for more details about this distribution.
++
+
apt (Ubuntu/Debian/etc.)
- Add the ArchiveBox repository to your sources.
@@ -241,6 +291,7 @@ archivebox init --setup # if any problems, install with pip insteadarchivebox server 0.0.0.0:8000 # completely optional, CLI can always be used without running a server # archivebox [subcommand] [--args] +archivebox help
debian-a
-
+
-
brew (macOS)
+ brew (macOS only)
- Install Homebrew on your system (if not already installed). @@ -269,6 +320,7 @@ archivebox init --setup # if any problems, install with pip instead
archivebox server 0.0.0.0:8000
# completely optional, CLI can always be used without running a server
# archivebox [subcommand] [--args]
+archivebox help
homebr
-
-
-
-See the
-
-
pip (macOS/Linux/BSD)
--
-
-
-
- Install Python >= v3.9 and Node >= v18 on your system (if not already installed). -
- Install the ArchiveBox package using
pip3. -
-pip3 install archivebox -
- - Create a new empty directory and initialize your collection (can be anywhere).
-
-mkdir ~/archivebox && cd ~/archivebox -archivebox init --setup -# install any missing extras like wget/git/ripgrep/etc. manually as needed -
- - Optional: Start the server then login to the Web UI http://127.0.0.1:8000 ⇢ Admin.
-
-archivebox server 0.0.0.0:8000 -# completely optional, CLI can always be used without running a server -# archivebox [subcommand] [--args] -
-
-See the
pip-archivebox repo for more details about this distribution.
--

pacman / 
pkg / 
nix (Arch/FreeBSD/NixOS/more)
@@ -345,7 +368,7 @@ See below for usage examples using the CLI, W
✨ Alpha (contributors wanted!): for more info, see the: Electron ArchiveBox repo. -
+
@@ -419,124 +442,133 @@ For more discussion on managed and paid hosting options see here:
+
-docker compose up -d # start the Web UI server in the background
-docker compose run archivebox add 'https://example.com' # add a test URL to snapshot w/ Docker Compose
-
-archivebox list 'https://example.com' # fetch it with pip-installed archivebox on the host
-docker compose run archivebox list 'https://example.com' # or w/ Docker Compose
-docker run -it -v $PWD:/data archivebox/archivebox list 'https://example.com' # or w/ Docker, all equivalent
-
-
- CLI Usage Examples (non-Docker)
CLI Usage Examples (non-Docker)
- -##### Bare Metal Usage (`pip`/`apt`/`brew`/etc.) - -
-
-
-
-Click to expand...
--
archivebox init --setup # safe to run init multiple times (also how you update versions)
-archivebox version # get archivebox version info and more
+archivebox version # get archivebox version info + check dependencies
+archivebox help # get list of archivebox subcommands that can be run
archivebox add --depth=1 'https://news.ycombinator.com'
- -##### Docker Compose Usage
+
-
-
-Click to expand...
+ Docker Compose CLI Usage Examples
-
# make sure you have `docker-compose.yml` from the Quickstart instructions first
docker compose run archivebox init --setup
docker compose run archivebox version
+docker compose run archivebox help
docker compose run archivebox add --depth=1 'https://news.ycombinator.com'
+# to start webserver: docker compose up
- -##### Docker Usage
+
-
-
+
+Click to expand...
+ Docker CLI Usage Examples
-
docker run -v $PWD:/data -it archivebox/archivebox init --setup
docker run -v $PWD:/data -it archivebox/archivebox version
+docker run -v $PWD:/data -it archivebox/archivebox help
+docker run -v $PWD:/data -it archivebox/archivebox add --depth=1 'https://news.ycombinator.com'
+# to start webserver: docker run -v $PWD:/data -it -p 8000:8000 archivebox/archivebox
++ +
+
+
+
+🗄 SQL/Python/Filesystem Usage
+
+archivebox shell # explore the Python library API in a REPL
+sqlite3 ./index.sqlite3 # run SQL queries directly on your index
+ls ./archive/*/index.html # or inspect snapshot data directly on the filesystem
++ +
+
+Optional: Change permissions to allow non-logged-in users + +
+
+🖥 Web UI Usage
+
+# Start the server on bare metal (pip/apt/brew/etc):
+archivebox manage createsuperuser # create a new admin user via CLI
+archivebox server 0.0.0.0:8000 # start the server
+
+# Or with Docker Compose:
+nano docker-compose.yml # setup initial ADMIN_USERNAME & ADMIN_PASSWORD
+docker compose up # start the server
+
+# Or with a Docker container:
+docker run -v $PWD:/data -it archivebox/archivebox archivebox manage createsuperuser
+docker run -v $PWD:/data -it -p 8000:8000 archivebox/archivebox
+http://localhost:8000 to see your server's Web UI ➡️
++Optional: Change permissions to allow non-logged-in users + +
+archivebox config --set PUBLIC_ADD_VIEW=True # allow guests to submit URLs
+archivebox config --set PUBLIC_SNAPSHOTS=True # allow guests to see snapshot content
+archivebox config --set PUBLIC_INDEX=True # allow guests to see list of all snapshots
+# or
+docker compose run archivebox config --set ...
+
+# restart the server to apply any config changes
++
+ +> [!TIP] +> Whether in Docker or not, ArchiveBox commands work the same way, and can be used to access the same data on-disk. +> For example, you could run the Web UI in Docker Compose, and run one-off commands with `pip`-installed ArchiveBox. + +
+
+ +
-Expand to show comparison...
+ +
+archivebox add --depth=1 'https://example.com' # add a URL with pip-installed archivebox on the host
+docker compose run archivebox add --depth=1 'https://example.com' # or w/ Docker Compose
+docker run -it -v $PWD:/data archivebox/archivebox add --depth=1 'https://example.com' # or w/ Docker, all equivalent
-#### Next Steps - -- `archivebox help/version` to see the list of available subcommands and currently installed version info -- `archivebox setup/init/config/status/manage` to administer your collection -- `archivebox add/schedule/remove/update/list/shell/oneshot` to manage Snapshots in the archive -- `archivebox schedule` to pull in fresh URLs regularly from [bookmarks/history/Pocket/Pinboard/RSS/etc.](#input-formats) - - -#### 🖥 Web UI Usage - -##### Start the Web Server -```bash -# Bare metal (pip/apt/brew/etc): -archivebox server 0.0.0.0:8000 # open http://127.0.0.1:8000 to view it - -# Docker Compose: -docker compose up - -# Docker: -docker run -v $PWD:/data -it -p 8000:8000 archivebox/archivebox -``` - -##### Allow Public Access or Create an Admin User -```bash -archivebox manage createsuperuser # create a new admin username & pass -# OR # OR -archivebox config --set PUBLIC_ADD_VIEW=True # allow guests to submit URLs -archivebox config --set PUBLIC_SNAPSHOTS=True # allow guests to see snapshot content -archivebox config --set PUBLIC_INDEX=True # allow guests to see list of all snapshots - -# restart the server to apply any config changes -``` - -*Docker hint:* Set the [`ADMIN_USERNAME` & `ADMIN_PASSWORD`)](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#admin_username--admin_password) env variables to auto-create an admin user on first-run. - -#### 🗄 SQL/Python/Filesystem Usage - -```bash -sqlite3 ./index.sqlite3 # run SQL queries on your index -archivebox shell # explore the Python API in a REPL -ls ./archive/*/index.html # or inspect snapshots on the filesystem -```
@@ -557,25 +589,28 @@ ls ./archive/*/index.html # or inspect snapshots on the filesystem
---
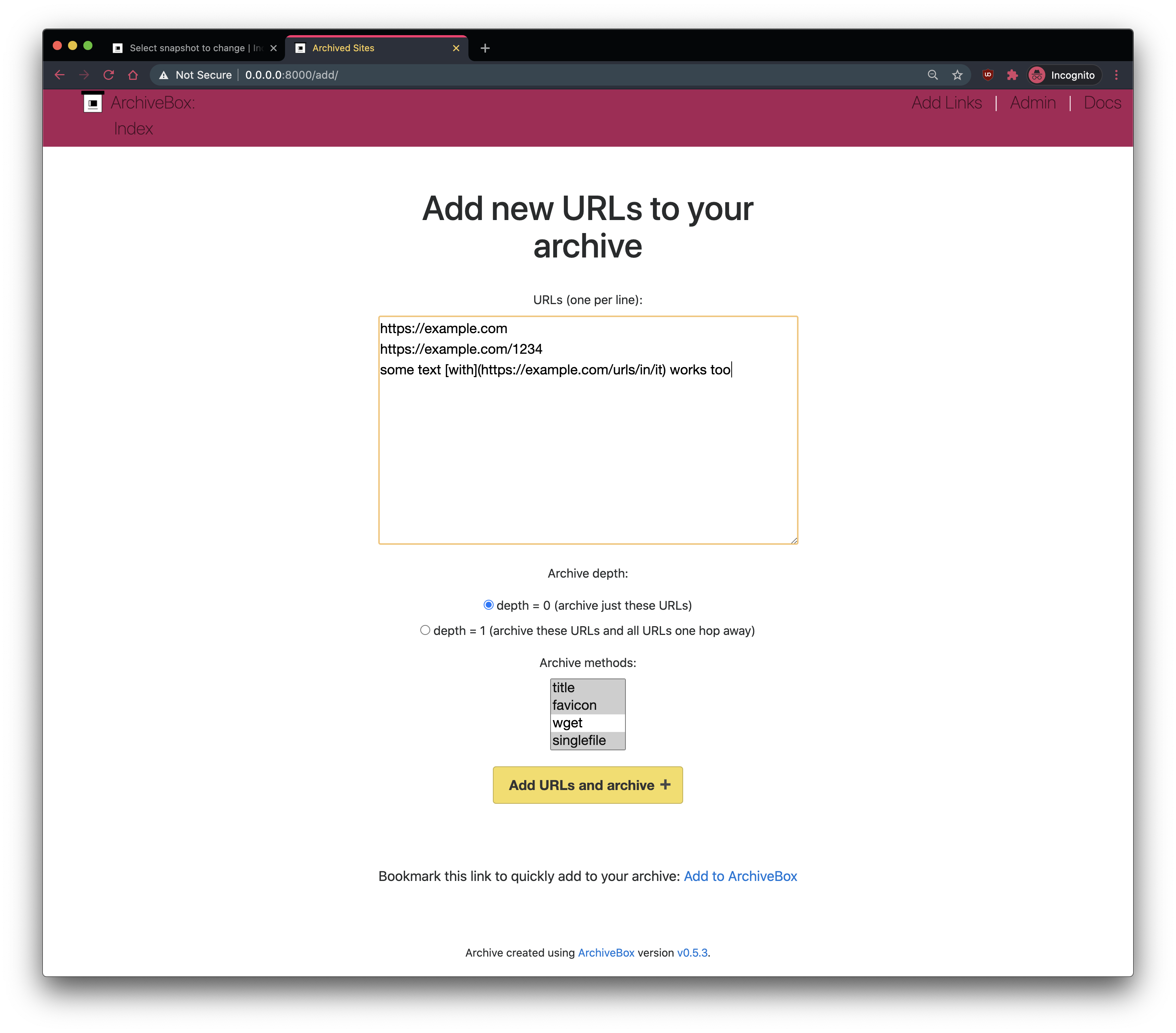
# Overview -## Input Formats + -ArchiveBox supports many input formats for URLs, including Pocket & Pinboard exports, Browser bookmarks, Browser history, plain text, HTML, markdown, and more! +## Input Formats: How to pass URLs into ArchiveBox for saving -*Click these links for instructions on how to prepare your links from these sources:* +- The official ArchiveBox Browser Extension (provides realtime archiving from Chrome/Chromium/Firefox browsers)
+
+-
The official ArchiveBox Browser Extension (provides realtime archiving from Chrome/Chromium/Firefox browsers)
+
+-  Manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, or [any other text-based format...](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file)
+
+-
Manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, or [any other text-based format...](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file)
+
+-  [MITM Proxy](https://mitmproxy.org/) archiving with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy) ([realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any device going through the proxy)
+
+-
[MITM Proxy](https://mitmproxy.org/) archiving with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy) ([realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any device going through the proxy)
+
+-  Exported [browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (see instructions for: [Chrome](https://support.google.com/chrome/answer/96816?hl=en), [Firefox](https://support.mozilla.org/en-US/kb/export-firefox-bookmarks-to-backup-or-transfer), [Safari](https://github.com/ArchiveBox/ArchiveBox/assets/511499/24ad068e-0fa6-41f4-a7ff-4c26fc91f71a), [IE](https://support.microsoft.com/en-us/help/211089/how-to-import-and-export-the-internet-explorer-favorites-folder-to-a-32-bit-version-of-windows), [Opera](https://help.opera.com/en/latest/features/#bookmarks:~:text=Click%20the%20import/-,export%20button,-on%20the%20bottom), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive))
+
+-
Exported [browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (see instructions for: [Chrome](https://support.google.com/chrome/answer/96816?hl=en), [Firefox](https://support.mozilla.org/en-US/kb/export-firefox-bookmarks-to-backup-or-transfer), [Safari](https://github.com/ArchiveBox/ArchiveBox/assets/511499/24ad068e-0fa6-41f4-a7ff-4c26fc91f71a), [IE](https://support.microsoft.com/en-us/help/211089/how-to-import-and-export-the-internet-explorer-favorites-folder-to-a-32-bit-version-of-windows), [Opera](https://help.opera.com/en/latest/features/#bookmarks:~:text=Click%20the%20import/-,export%20button,-on%20the%20bottom), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive))
+
+-  Links from [Pocket](https://getpocket.com/export), [Pinboard](https://pinboard.in/export/), [Instapaper](https://www.instapaper.com/user), [Shaarli](https://shaarli.readthedocs.io/en/master/Usage/#importexport), [Delicious](https://www.groovypost.com/howto/howto/export-delicious-bookmarks-xml/), [Reddit Saved](https://github.com/csu/export-saved-reddit), [Wallabag](https://doc.wallabag.org/en/user/import/wallabagv2.html), [Unmark.it](http://help.unmark.it/import-export), [OneTab](https://www.addictivetips.com/web/onetab-save-close-all-chrome-tabs-to-restore-export-or-import/), [Firefox Sync](https://github.com/ArchiveBox/ArchiveBox/issues/648), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive)
-- TXT, RSS, XML, JSON, CSV, SQL, HTML, Markdown, or [any other text-based format...](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file)
-- [Browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (see instructions for: [Chrome](https://support.google.com/chrome/answer/96816?hl=en), [Firefox](https://support.mozilla.org/en-US/kb/export-firefox-bookmarks-to-backup-or-transfer), [Safari](https://github.com/ArchiveBox/ArchiveBox/assets/511499/24ad068e-0fa6-41f4-a7ff-4c26fc91f71a), [IE](https://support.microsoft.com/en-us/help/211089/how-to-import-and-export-the-internet-explorer-favorites-folder-to-a-32-bit-version-of-windows), [Opera](https://help.opera.com/en/latest/features/#bookmarks:~:text=Click%20the%20import/-,export%20button,-on%20the%20bottom), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive))
-- Browser extension [`archivebox-exporter`](https://github.com/ArchiveBox/archivebox-extension) (realtime archiving from Chrome/Chromium/Firefox)
-- [Pocket](https://getpocket.com/export), [Pinboard](https://pinboard.in/export/), [Instapaper](https://www.instapaper.com/user), [Shaarli](https://shaarli.readthedocs.io/en/master/Usage/#importexport), [Delicious](https://www.groovypost.com/howto/howto/export-delicious-bookmarks-xml/), [Reddit Saved](https://github.com/csu/export-saved-reddit), [Wallabag](https://doc.wallabag.org/en/user/import/wallabagv2.html), [Unmark.it](http://help.unmark.it/import-export), [OneTab](https://www.addictivetips.com/web/onetab-save-close-all-chrome-tabs-to-restore-export-or-import/), [Firefox Sync](https://github.com/ArchiveBox/ArchiveBox/issues/648), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive)
-- Proxy archiving with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy) ([realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any browser or device)
Links from [Pocket](https://getpocket.com/export), [Pinboard](https://pinboard.in/export/), [Instapaper](https://www.instapaper.com/user), [Shaarli](https://shaarli.readthedocs.io/en/master/Usage/#importexport), [Delicious](https://www.groovypost.com/howto/howto/export-delicious-bookmarks-xml/), [Reddit Saved](https://github.com/csu/export-saved-reddit), [Wallabag](https://doc.wallabag.org/en/user/import/wallabagv2.html), [Unmark.it](http://help.unmark.it/import-export), [OneTab](https://www.addictivetips.com/web/onetab-save-close-all-chrome-tabs-to-restore-export-or-import/), [Firefox Sync](https://github.com/ArchiveBox/ArchiveBox/issues/648), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive)
-- TXT, RSS, XML, JSON, CSV, SQL, HTML, Markdown, or [any other text-based format...](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file)
-- [Browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (see instructions for: [Chrome](https://support.google.com/chrome/answer/96816?hl=en), [Firefox](https://support.mozilla.org/en-US/kb/export-firefox-bookmarks-to-backup-or-transfer), [Safari](https://github.com/ArchiveBox/ArchiveBox/assets/511499/24ad068e-0fa6-41f4-a7ff-4c26fc91f71a), [IE](https://support.microsoft.com/en-us/help/211089/how-to-import-and-export-the-internet-explorer-favorites-folder-to-a-32-bit-version-of-windows), [Opera](https://help.opera.com/en/latest/features/#bookmarks:~:text=Click%20the%20import/-,export%20button,-on%20the%20bottom), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive))
-- Browser extension [`archivebox-exporter`](https://github.com/ArchiveBox/archivebox-extension) (realtime archiving from Chrome/Chromium/Firefox)
-- [Pocket](https://getpocket.com/export), [Pinboard](https://pinboard.in/export/), [Instapaper](https://www.instapaper.com/user), [Shaarli](https://shaarli.readthedocs.io/en/master/Usage/#importexport), [Delicious](https://www.groovypost.com/howto/howto/export-delicious-bookmarks-xml/), [Reddit Saved](https://github.com/csu/export-saved-reddit), [Wallabag](https://doc.wallabag.org/en/user/import/wallabagv2.html), [Unmark.it](http://help.unmark.it/import-export), [OneTab](https://www.addictivetips.com/web/onetab-save-close-all-chrome-tabs-to-restore-export-or-import/), [Firefox Sync](https://github.com/ArchiveBox/ArchiveBox/issues/648), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive)
-- Proxy archiving with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy) ([realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any browser or device)
 @@ -601,30 +636,41 @@ It also includes a built-in scheduled import feature with `archivebox schedule`
@@ -601,30 +636,41 @@ It also includes a built-in scheduled import feature with `archivebox schedule`
-## Output Formats -Inside each Snapshot folder, ArchiveBox saves these different types of extractor outputs as plain files: + + +## Output Formats: What ArchiveBox saves for each URL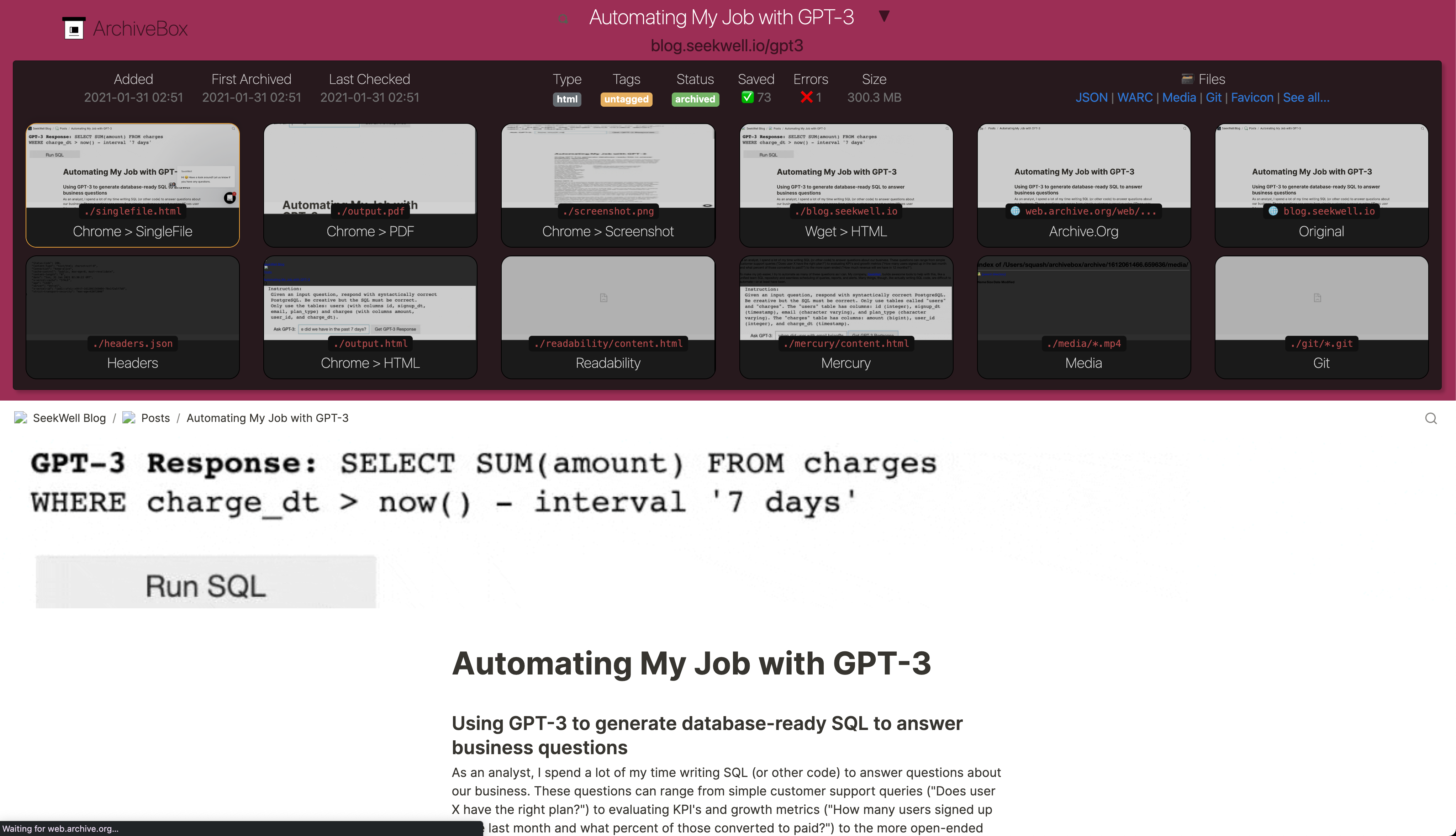 -`./archive/TIMESTAMP/*`
-- **Index:** `index.html` & `index.json` HTML and JSON index files containing metadata and details
-- **Title**, **Favicon**, **Headers** Response headers, site favicon, and parsed site title
-- **SingleFile:** `singlefile.html` HTML snapshot rendered with headless Chrome using SingleFile
-- **Wget Clone:** `example.com/page-name.html` wget clone of the site with `warc/TIMESTAMP.gz`
-- Chrome Headless
- - **PDF:** `output.pdf` Printed PDF of site using headless chrome
- - **Screenshot:** `screenshot.png` 1440x900 screenshot of site using headless chrome
- - **DOM Dump:** `output.html` DOM Dump of the HTML after rendering using headless chrome
-- **Article Text:** `article.html/json` Article text extraction using Readability & Mercury
-- **Archive.org Permalink:** `archive.org.txt` A link to the saved site on archive.org
-- **Audio & Video:** `media/` all audio/video files + playlists, including subtitles & metadata with youtube-dl (or yt-dlp)
-- **Source Code:** `git/` clone of any repository found on GitHub, Bitbucket, or GitLab links
-- _More coming soon! See the [Roadmap](https://github.com/ArchiveBox/ArchiveBox/wiki/Roadmap)..._
+For each web page added, ArchiveBox creates a Snapshot folder and preserves its content as ordinary files inside the folder (e.g. HTML, PDF, PNG, JSON, etc.).
-It does everything out-of-the-box by default, but you can disable or tweak [individual archive methods](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) via environment variables / config.
+It uses all available methods out-of-the-box, but you can disable extractors and fine-tune the [configuration](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed.
+
-`./archive/TIMESTAMP/*`
-- **Index:** `index.html` & `index.json` HTML and JSON index files containing metadata and details
-- **Title**, **Favicon**, **Headers** Response headers, site favicon, and parsed site title
-- **SingleFile:** `singlefile.html` HTML snapshot rendered with headless Chrome using SingleFile
-- **Wget Clone:** `example.com/page-name.html` wget clone of the site with `warc/TIMESTAMP.gz`
-- Chrome Headless
- - **PDF:** `output.pdf` Printed PDF of site using headless chrome
- - **Screenshot:** `screenshot.png` 1440x900 screenshot of site using headless chrome
- - **DOM Dump:** `output.html` DOM Dump of the HTML after rendering using headless chrome
-- **Article Text:** `article.html/json` Article text extraction using Readability & Mercury
-- **Archive.org Permalink:** `archive.org.txt` A link to the saved site on archive.org
-- **Audio & Video:** `media/` all audio/video files + playlists, including subtitles & metadata with youtube-dl (or yt-dlp)
-- **Source Code:** `git/` clone of any repository found on GitHub, Bitbucket, or GitLab links
-- _More coming soon! See the [Roadmap](https://github.com/ArchiveBox/ArchiveBox/wiki/Roadmap)..._
+For each web page added, ArchiveBox creates a Snapshot folder and preserves its content as ordinary files inside the folder (e.g. HTML, PDF, PNG, JSON, etc.).
-It does everything out-of-the-box by default, but you can disable or tweak [individual archive methods](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) via environment variables / config.
+It uses all available methods out-of-the-box, but you can disable extractors and fine-tune the [configuration](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed.
+
+
## Configuration @@ -632,52 +678,56 @@ It does everything out-of-the-box by default, but you can disable or tweak [indi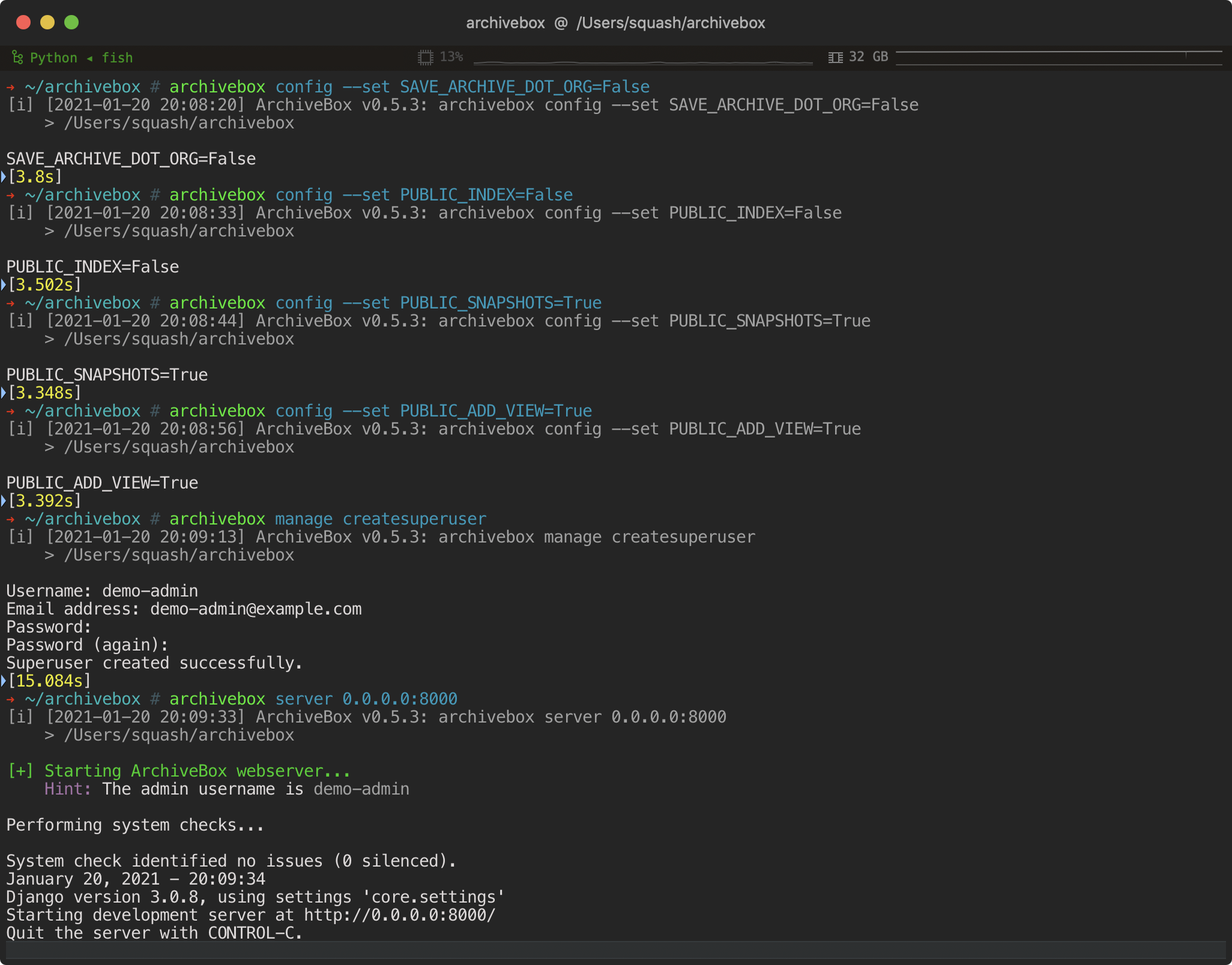 ArchiveBox can be configured via environment variables, by using the `archivebox config` CLI, or by editing `./ArchiveBox.conf` directly.
-
-```bash
-archivebox config # view the entire config
+
ArchiveBox can be configured via environment variables, by using the `archivebox config` CLI, or by editing `./ArchiveBox.conf` directly.
-
-```bash
-archivebox config # view the entire config
+
+
-These methods also work the same way when run inside Docker, see the Docker Configuration wiki page for details. +The configuration is documented here: **[Configuration Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration)**, and loaded here: [`archivebox/config.py`](https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/config.py). -**The config loading logic with all the options defined is here: [`archivebox/config.py`](https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/config.py).** - -Most options are also documented on the **[Configuration Wiki page](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration)**. - -#### Most Common Options to Tweak - -```bash + +
## Dependencies -To achieve high-fidelity archives in as many situations as possible, ArchiveBox depends on a variety of 3rd-party tools that specialize in extracting different types of content. +To achieve high-fidelity archives in as many situations as possible, ArchiveBox depends on a variety of 3rd-party libraries and tools that specialize in extracting different types of content. + +> Under-the-hood, ArchiveBox uses [Django](https://www.djangoproject.com/start/overview/) to power its [Web UI](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#ui-usage) and [SQlite](https://www.sqlite.org/locrsf.html) + the filesystem to provide [fast & durable metadata storage](https://www.sqlite.org/locrsf.html) w/ [determinisitc upgrades](https://stackoverflow.com/a/39976321/2156113). ArchiveBox bundles industry-standard tools like [Google Chrome](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install), [`wget`, `yt-dlp`, `readability`, etc.](#dependencies) internally, and its operation can be [tuned, secured, and extended](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed for many different applications. +
- +
+
# Overview -## Input Formats + -ArchiveBox supports many input formats for URLs, including Pocket & Pinboard exports, Browser bookmarks, Browser history, plain text, HTML, markdown, and more! +## Input Formats: How to pass URLs into ArchiveBox for saving -*Click these links for instructions on how to prepare your links from these sources:* +-
-## Output Formats -Inside each Snapshot folder, ArchiveBox saves these different types of extractor outputs as plain files: + + +## Output Formats: What ArchiveBox saves for each URL
+
+
+
Expand to see the full list of ways ArchiveBox saves each page...
+ + +./archive/{Snapshot.id}/+
-
+
- Index:
index.html&index.jsonHTML and JSON index files containing metadata and details
+ - Title, Favicon, Headers Response headers, site favicon, and parsed site title +
- SingleFile:
singlefile.htmlHTML snapshot rendered with headless Chrome using SingleFile
+ - Wget Clone:
example.com/page-name.htmlwget clone of the site withwarc/TIMESTAMP.gz
+ - Chrome Headless
-
+
- PDF:
output.pdfPrinted PDF of site using headless chrome
+ - Screenshot:
screenshot.png1440x900 screenshot of site using headless chrome
+ - DOM Dump:
output.htmlDOM Dump of the HTML after rendering using headless chrome
+
+ - PDF:
- Article Text:
article.html/jsonArticle text extraction using Readability & Mercury
+ - Archive.org Permalink:
archive.org.txtA link to the saved site on archive.org
+ - Audio & Video:
media/all audio/video files + playlists, including subtitles & metadata with youtube-dl (or yt-dlp)
+ - Source Code:
git/clone of any repository found on GitHub, Bitbucket, or GitLab links
+ - More coming soon! See the Roadmap... +
## Configuration @@ -632,52 +678,56 @@ It does everything out-of-the-box by default, but you can disable or tweak [indi
+
+
Expand to see examples...
+archivebox config # view the entire config
archivebox config --get CHROME_BINARY # view a specific value
-
+
archivebox config --set CHROME_BINARY=chromium # persist a config using CLI
# OR
echo CHROME_BINARY=chromium >> ArchiveBox.conf # persist a config using file
# OR
env CHROME_BINARY=chromium archivebox ... # run with a one-off config
-```
+-These methods also work the same way when run inside Docker, see the Docker Configuration wiki page for details. +The configuration is documented here: **[Configuration Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration)**, and loaded here: [`archivebox/config.py`](https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/config.py). -**The config loading logic with all the options defined is here: [`archivebox/config.py`](https://github.com/ArchiveBox/ArchiveBox/blob/dev/archivebox/config.py).** - -Most options are also documented on the **[Configuration Wiki page](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration)**. - -#### Most Common Options to Tweak - -```bash + +
+
Expand to see the most common options to tweak...
+
# e.g. archivebox config --set TIMEOUT=120
-
+# or docker compose run archivebox config --set TIMEOUT=120
+
TIMEOUT=120 # default: 60 add more seconds on slower networks
CHECK_SSL_VALIDITY=True # default: False True = allow saving URLs w/ bad SSL
SAVE_ARCHIVE_DOT_ORG=False # default: True False = disable Archive.org saving
MAX_MEDIA_SIZE=1500m # default: 750m raise/lower youtubedl output size
-
+
PUBLIC_INDEX=True # default: True whether anon users can view index
PUBLIC_SNAPSHOTS=True # default: True whether anon users can view pages
PUBLIC_ADD_VIEW=False # default: False whether anon users can add new URLs
-
+
CHROME_USER_AGENT="Mozilla/5.0 ..." # change these to get around bot blocking
WGET_USER_AGENT="Mozilla/5.0 ..."
CURL_USER_AGENT="Mozilla/5.0 ..."
-```
-
+## Dependencies -To achieve high-fidelity archives in as many situations as possible, ArchiveBox depends on a variety of 3rd-party tools that specialize in extracting different types of content. +To achieve high-fidelity archives in as many situations as possible, ArchiveBox depends on a variety of 3rd-party libraries and tools that specialize in extracting different types of content. + +> Under-the-hood, ArchiveBox uses [Django](https://www.djangoproject.com/start/overview/) to power its [Web UI](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#ui-usage) and [SQlite](https://www.sqlite.org/locrsf.html) + the filesystem to provide [fast & durable metadata storage](https://www.sqlite.org/locrsf.html) w/ [determinisitc upgrades](https://stackoverflow.com/a/39976321/2156113). ArchiveBox bundles industry-standard tools like [Google Chrome](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install), [`wget`, `yt-dlp`, `readability`, etc.](#dependencies) internally, and its operation can be [tuned, secured, and extended](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed for many different applications. +
-
+
> *TIP: For better security, easier updating, and to avoid polluting your host system with extra dependencies,**it is strongly recommended to use the [⭐️ official Docker image](https://github.com/ArchiveBox/ArchiveBox/wiki/Docker)** with everything pre-installed for the best experience.* @@ -724,14 +774,13 @@ Installing directly on **Windows without Docker or WSL/WSL2/Cygwin is not offici ## Archive Layout -All of ArchiveBox's state (including the SQLite DB, archived assets, config, logs, etc.) is stored in a single folder called the "ArchiveBox Data Folder". -Data folders can be created anywhere (`~/archivebox` or `$PWD/data` as seen in our examples), and you can create more than one for different collections. +All of ArchiveBox's state (SQLite DB, archived assets, config, logs, etc.) is stored in a single folder called the "ArchiveBox Data Folder".
- +Data folders can be created anywhere (`~/archivebox` or `$PWD/data` as seen in our examples), and you can create as many data folders as you want to hold different collections. All
Expand to learn more about ArchiveBox's dependencies...
+
Expand to learn more about ArchiveBox's internals & dependencies...
> *TIP: For better security, easier updating, and to avoid polluting your host system with extra dependencies,**it is strongly recommended to use the [⭐️ official Docker image](https://github.com/ArchiveBox/ArchiveBox/wiki/Docker)** with everything pre-installed for the best experience.* @@ -724,14 +774,13 @@ Installing directly on **Windows without Docker or WSL/WSL2/Cygwin is not offici ## Archive Layout -All of ArchiveBox's state (including the SQLite DB, archived assets, config, logs, etc.) is stored in a single folder called the "ArchiveBox Data Folder". -Data folders can be created anywhere (`~/archivebox` or `$PWD/data` as seen in our examples), and you can create more than one for different collections. +All of ArchiveBox's state (SQLite DB, archived assets, config, logs, etc.) is stored in a single folder called the "ArchiveBox Data Folder".
Expand to learn more about the layout of Archivebox's data on-disk...
- +Data folders can be created anywhere (`~/archivebox` or `$PWD/data` as seen in our examples), and you can create as many data folders as you want to hold different collections. All
archivebox CLI commands are designed to be run from inside an ArchiveBox data folder, starting with archivebox init to initialize a new collection inside an empty directory.
mkdir ~/archivebox && cd ~/archivebox # just an example, can be anywhere
@@ -774,7 +823,7 @@ Each snapshot subfolder ./archive/TIMESTAMP/ includes a static
----
-
 @@ -823,7 +873,7 @@ If you're importing pages with private content or URLs containing secret tokens
@@ -823,7 +873,7 @@ If you're importing pages with private content or URLs containing secret tokens
-Click to expand...
+Expand to learn about privacy, permissions, and user accounts...
```bash
@@ -838,6 +888,7 @@ archivebox config --set SAVE_ARCHIVE_DOT_ORG=False # disable saving all URLs in
archivebox config --set PUBLIC_INDEX=False
archivebox config --set PUBLIC_SNAPSHOTS=False
archivebox config --set PUBLIC_ADD_VIEW=False
+archivebox manage createsuperuser
# if extra paranoid or anti-Google:
archivebox config --set SAVE_FAVICON=False # disable favicon fetching (it calls a Google API passing the URL's domain part only)
@@ -867,7 +918,7 @@ Be aware that malicious archived JS can access the contents of other pages in yo
-Click to expand...
+Expand to see risks and mitigations...
```bash
@@ -903,7 +954,7 @@ For various reasons, many large sites (Reddit, Twitter, Cloudflare, etc.) active
-Click to expand...
+Click to learn how to set up user agents, cookies, and site logins...
@@ -926,7 +977,7 @@ ArchiveBox appends a hash with the current date `https://example.com#2020-10-24`
-Click to expand...
+Click to learn how the `Re-Snapshot` feature works...
@@ -954,12 +1005,11 @@ Improved support for saving multiple snapshots of a single URL without this hash
### Storage Requirements
-Because ArchiveBox is designed to ingest a large volume of URLs with multiple copies of each URL stored by different 3rd-party tools, it can be quite disk-space intensive.
-There also also some special requirements when using filesystems like NFS/SMB/FUSE.
+Because ArchiveBox is designed to ingest a large volume of URLs with multiple copies of each URL stored by different 3rd-party tools, it can be quite disk-space intensive. There are also some special requirements when using filesystems like NFS/SMB/FUSE.
-Click to expand...
+Click to learn more about ArchiveBox's filesystem and hosting requirements...
@@ -1030,10 +1080,6 @@ If using Docker or NFS/SMB/FUSE for the `data/archive/` folder, you may need to
- ---- - -
-
@@ -1082,7 +1128,7 @@ A variety of open and closed-source archiving projects exist, but few provide a
Click to read more...
+Click to read more about why archiving is important and how to do it ethically...
@@ -1082,7 +1128,7 @@ A variety of open and closed-source archiving projects exist, but few provide a
-
+
ArchiveBox tries to be a robust, set-and-forget archiving solution suitable for archiving RSS feeds, bookmarks, or your entire browsing history (beware, it may be too big to store), including private/authenticated content that you wouldn't otherwise share with a centralized service. @@ -1111,33 +1157,21 @@ ArchiveBox is neither the highest fidelity nor the simplest tool available for s
- -
-Our Community Wiki page serves as an index of the broader web archiving community.
-
-
-
-Our Community Wiki page serves as an index of the broader web archiving community.
-
-
Click to read more...
+
Click to read about how we differ from other centralized archiving services and open source tools...
ArchiveBox tries to be a robust, set-and-forget archiving solution suitable for archiving RSS feeds, bookmarks, or your entire browsing history (beware, it may be too big to store), including private/authenticated content that you wouldn't otherwise share with a centralized service. @@ -1111,33 +1157,21 @@ ArchiveBox is neither the highest fidelity nor the simplest tool available for s
-
-
- -
-
+
## Internet Archiving Ecosystem
-
-
-
- See where archivists hang out online -
- Explore other open-source tools for your web archiving needs -
- Learn which organizations are the big players in the web archiving space -
-
- [Community Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community) - - [The Master Lists](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#the-master-lists) - _Community-maintained indexes of archiving tools and institutions._ - [Web Archiving Software](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#web-archiving-projects) - _Open source tools and projects in the internet archiving space._ + _List of ArchiveBox alternatives and open source projects in the internet archiving space._ + - [Awesome-Web-Archiving Lists](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#the-master-lists) + _Community-maintained indexes of archiving tools and institutions like `iipc/awesome-web-archiving`._ - [Reading List](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#reading-list) _Articles, posts, and blogs relevant to ArchiveBox and web archiving in general._ - [Communities](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#communities) @@ -1154,11 +1188,8 @@ Our Community Wiki page serves as an index of the broader web archiving communit > ✨ **[Hire the team that built Archivebox](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102) to work on your project.** ([@ArchiveBoxApp](https://twitter.com/ArchiveBoxApp)) -(We also offer general software consulting across many industries) -
----
 @@ -1333,28 +1364,19 @@ archivebox init --setup
-#### Run the linters
+#### Run the linters / tests
-
-#### Run the integration tests
-
-
+
#### Make migrations or enter a django shell
@@ -1333,28 +1364,19 @@ archivebox init --setup
-#### Run the linters
+#### Run the linters / tests
-
-#### Run the integration tests
-
-
+
#### Make migrations or enter a django shell
 +
+- [ArchiveBox.io Homepage](https://archivebox.io) / [Source Code (Github)](https://github.com/ArchiveBox/ArchiveBox) / [Demo Server](https://demo.archivebox.io)
+- [Documentation Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki) / [API Reference Docs](https://docs.archivebox.io) / [Changelog](https://github.com/ArchiveBox/ArchiveBox/releases)
+- [Bug Tracker](https://github.com/ArchiveBox/ArchiveBox/issues) / [Discussions](https://github.com/ArchiveBox/ArchiveBox/discussions) / [Community Chat Forum (Zulip)](https://zulip.archivebox.io)
- Social Media: [Twitter](https://twitter.com/ArchiveBoxApp), [LinkedIn](https://www.linkedin.com/company/archivebox/), [YouTube](https://www.youtube.com/@ArchiveBoxApp), [Alternative.to](https://alternativeto.net/software/archivebox/about/), [Reddit](https://www.reddit.com/r/ArchiveBox/)
-- Donations: [Github.com/ArchiveBox/ArchiveBox/wiki/Donations](https://github.com/ArchiveBox/ArchiveBox/wiki/Donations)
---
+
+
+- [ArchiveBox.io Homepage](https://archivebox.io) / [Source Code (Github)](https://github.com/ArchiveBox/ArchiveBox) / [Demo Server](https://demo.archivebox.io)
+- [Documentation Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki) / [API Reference Docs](https://docs.archivebox.io) / [Changelog](https://github.com/ArchiveBox/ArchiveBox/releases)
+- [Bug Tracker](https://github.com/ArchiveBox/ArchiveBox/issues) / [Discussions](https://github.com/ArchiveBox/ArchiveBox/discussions) / [Community Chat Forum (Zulip)](https://zulip.archivebox.io)
- Social Media: [Twitter](https://twitter.com/ArchiveBoxApp), [LinkedIn](https://www.linkedin.com/company/archivebox/), [YouTube](https://www.youtube.com/@ArchiveBoxApp), [Alternative.to](https://alternativeto.net/software/archivebox/about/), [Reddit](https://www.reddit.com/r/ArchiveBox/)
-- Donations: [Github.com/ArchiveBox/ArchiveBox/wiki/Donations](https://github.com/ArchiveBox/ArchiveBox/wiki/Donations)
---
+
Explore our index of web archiving software, blogs, and communities around the world...
+Our Community Wiki strives to be a comprehensive index of the broader web archiving community...
- [Community Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community) - - [The Master Lists](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#the-master-lists) - _Community-maintained indexes of archiving tools and institutions._ - [Web Archiving Software](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#web-archiving-projects) - _Open source tools and projects in the internet archiving space._ + _List of ArchiveBox alternatives and open source projects in the internet archiving space._ + - [Awesome-Web-Archiving Lists](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#the-master-lists) + _Community-maintained indexes of archiving tools and institutions like `iipc/awesome-web-archiving`._ - [Reading List](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#reading-list) _Articles, posts, and blogs relevant to ArchiveBox and web archiving in general._ - [Communities](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community#communities) @@ -1154,11 +1188,8 @@ Our Community Wiki page serves as an index of the broader web archiving communit > ✨ **[Hire the team that built Archivebox](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102) to work on your project.** ([@ArchiveBoxApp](https://twitter.com/ArchiveBoxApp)) -(We also offer general software consulting across many industries) -
----
Click to expand...
```bash ./bin/lint.sh -``` -(uses `flake8` and `mypy`) - -Click to expand...
- -```bash ./bin/test.sh ``` -(uses `pytest -s`) +(uses `flake8`, `mypy`, and `pytest -s`)Click to expand...
@@ -1449,47 +1471,31 @@ Extractors take the URL of a page to archive, write their output to the filesyst ## Further Reading -- Home: [ArchiveBox.io](https://archivebox.io) -- Demo: [Demo.ArchiveBox.io](https://demo.archivebox.io) -- Docs: [Docs.ArchiveBox.io](https://docs.archivebox.io) -- Releases: [Github.com/ArchiveBox/ArchiveBox/releases](https://github.com/ArchiveBox/ArchiveBox/releases) -- Wiki: [Github.com/ArchiveBox/ArchiveBox/wiki](https://github.com/ArchiveBox/ArchiveBox/wiki) -- Issues: [Github.com/ArchiveBox/ArchiveBox/issues](https://github.com/ArchiveBox/ArchiveBox/issues) -- Discussions: [Github.com/ArchiveBox/ArchiveBox/discussions](https://github.com/ArchiveBox/ArchiveBox/discussions) -- Community Chat: [Zulip Chat (preferred)](https://zulip.archivebox.io) or [Matrix Chat (old)](https://app.element.io/#/room/#archivebox:matrix.org) +
+
+- [ArchiveBox.io Homepage](https://archivebox.io) / [Source Code (Github)](https://github.com/ArchiveBox/ArchiveBox) / [Demo Server](https://demo.archivebox.io)
+- [Documentation Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki) / [API Reference Docs](https://docs.archivebox.io) / [Changelog](https://github.com/ArchiveBox/ArchiveBox/releases)
+- [Bug Tracker](https://github.com/ArchiveBox/ArchiveBox/issues) / [Discussions](https://github.com/ArchiveBox/ArchiveBox/discussions) / [Community Chat Forum (Zulip)](https://zulip.archivebox.io)
- Social Media: [Twitter](https://twitter.com/ArchiveBoxApp), [LinkedIn](https://www.linkedin.com/company/archivebox/), [YouTube](https://www.youtube.com/@ArchiveBoxApp), [Alternative.to](https://alternativeto.net/software/archivebox/about/), [Reddit](https://www.reddit.com/r/ArchiveBox/)
-- Donations: [Github.com/ArchiveBox/ArchiveBox/wiki/Donations](https://github.com/ArchiveBox/ArchiveBox/wiki/Donations)
---
+
+🏛️ Contact us for professional support 💬
-
-
- -This project is maintained mostly in my spare time with the help from generous contributors. - - -
- -**🏛️ [Contact us for professional support](https://docs.sweeting.me/s/archivebox-consulting-services) 💬** - -
-
 -
- -
-
-
-
-ArchiveBox operates as a US 501(c)(3) nonprofit, donations are tax-deductible.
(fiscally sponsored by HCB
- -(网站存档 / 爬虫) - - -
- -
-
-
-
-
-✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit... +
+ +
+
+ArchiveBox operates as a US 501(c)(3) nonprofit (sponsored by HCB), donations are tax-deductible. +
+
+
+
+ArchiveBox was started by Nick Sweeting in 2017, and has grown steadily with help from our amazing contributors. +
+✨ Have spare CPU/disk/bandwidth after all your 网站存档爬 and want to help the world?
Check out our Good Karma Kit...
-
-- -This project is maintained mostly in my spare time with the help from generous contributors. - - -
- -**🏛️ [Contact us for professional support](https://docs.sweeting.me/s/archivebox-consulting-services) 💬** - -
-
-ArchiveBox operates as a US 501(c)(3) nonprofit, donations are tax-deductible.
(fiscally sponsored by HCB
EIN: 81-2908499)- -(网站存档 / 爬虫) - -
-
--
-✨ Have spare CPU/disk/bandwidth and want to help the world?
Check out our Good Karma Kit... +
+ArchiveBox operates as a US 501(c)(3) nonprofit (sponsored by HCB), donations are tax-deductible. +
+
++ArchiveBox was started by Nick Sweeting in 2017, and has grown steadily with help from our amazing contributors. +
+✨ Have spare CPU/disk/bandwidth after all your 网站存档爬 and want to help the world?
Check out our Good Karma Kit...